When training large language models, the quality of the data is as crucial as its quantity. This concept can be explored by looking at the “Language Models are Few-Shot Learners” paper by OpenAI, which delves into the training process of GPT-3.
The Raw Data Problem
GPT-3’s training began with a staggering 45 TB of compressed plaintext data collected from monthly Common Crawl datasets spanning 2016 to 2019. The researchers noted that this volume was sufficient to train even their largest models without repeating sequences. However, they discovered that filtering this data significantly enhanced model performance. The filtering process involved two key steps:
- Filtering data based on similarity to high-quality reference corpora.
- Conducting fuzzy deduplication to eliminate redundancy and prevent overfitting.
These steps reduced the dataset from 45TB to just 570GB — a 98.7% reduction. Despite the dramatic decrease in volume, the filtered data outperformed the unfiltered data.
High-Quality Supplements
Even after filtering, the researchers recognized the need for additional high-quality data sources:
- WebText2 — 40 GB of content scraped from web links found in up-voted Reddit posts.
- Books1 — Likely the BookCorpus dataset containing 7,185 unique self-published books with at least 20,000 words each.
- Books2 — Details remain undisclosed, but likely contains around 9GB of high-quality technical reference materials.
- Wikipedia (English) — Approximately 4.5 billion words, translating to around 27GB of text data.
These sources feature an extra layer of human input, distinguishing them from raw web-scraped data. WebText2 relies on community-curated links via Reddit up-votes. Books1 includes self-published long-form texts. Wikipedia stands as a great source for a broad range of high-quality information.
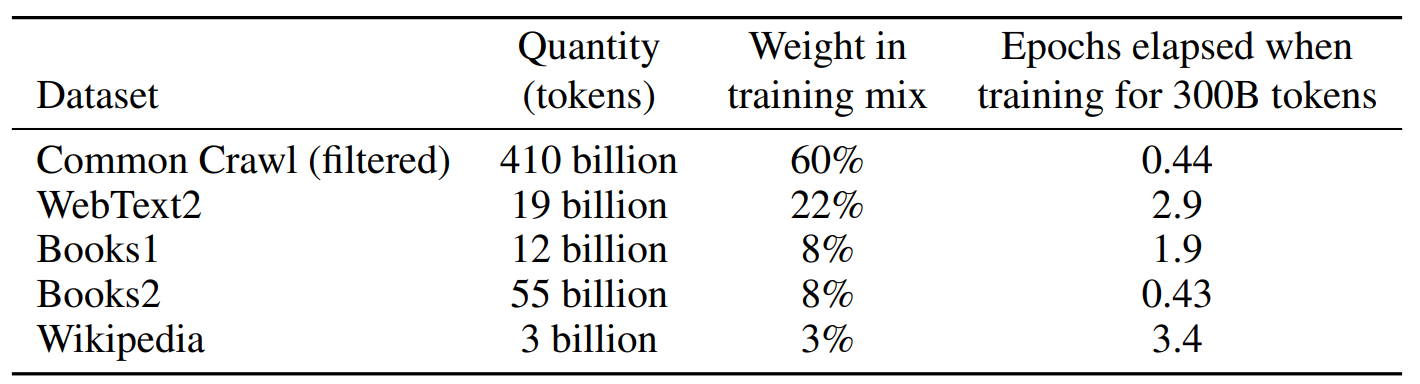
Oversampling Quality
Statistics from the GPT-3 training process reveal how frequently each dataset was utilized on average during the training of 300 billion tokens:
| Dataset | Usage frequency |
|---|---|
| Wikipedia | 3.4× |
| WebText2 | 2.9× |
| Books1 | 1.9× |
| Common Crawl (filtered) | 0.44× |
| Books2 | 0.43× |
This data underscores the necessity of not only including high-quality sources but also oversampling them to optimize the model. Wikipedia, WebText2, and Books1 were used significantly more than the filtered Common Crawl data, by factors ranging from 4.3 to 7.7 times on a per-unit basis.
The Takeaway
Although 45TB of unfiltered web data was available, the optimal performance was achieved with a curated and oversampled set of high-quality sources totaling approximately 650GB. This raises important questions about the future of large-scale, high-quality datasets as models continue to grow in complexity and size. Who will be responsible for creating these datasets, and what legal considerations will arise?