The rapid increase in model parameters and training data for LLMs has led to a significant rise in compute and power requirements. Let’s delve into the compute and energy demands of LLMs by examining details from OpenAI’s GPT-3 publication.
Measuring Compute
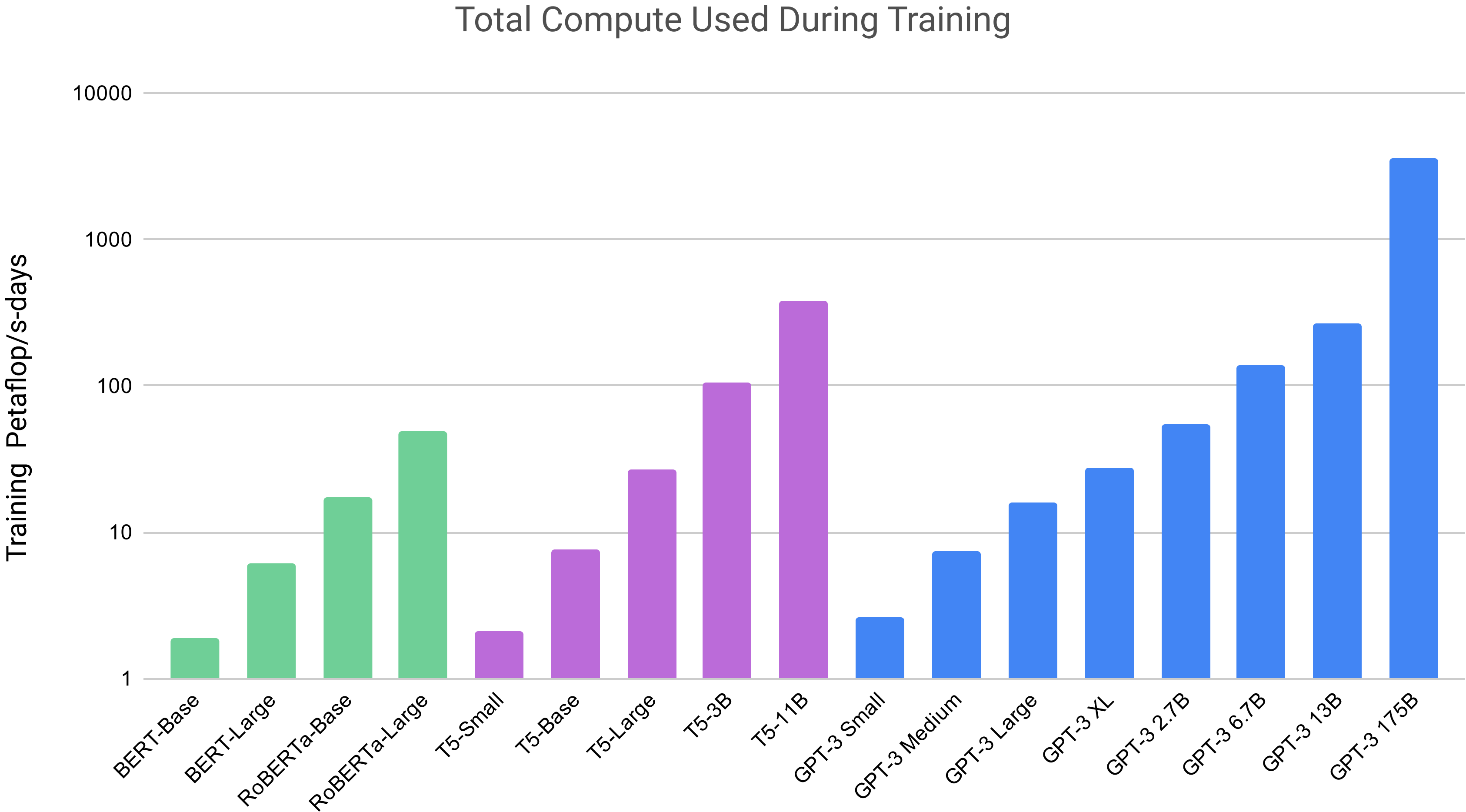
Compute needs are often expressed in petaflop/s-days. One petaflop/s equals one quadrillion floating-point operations per second, and “days” indicates the duration for which this performance is sustained.
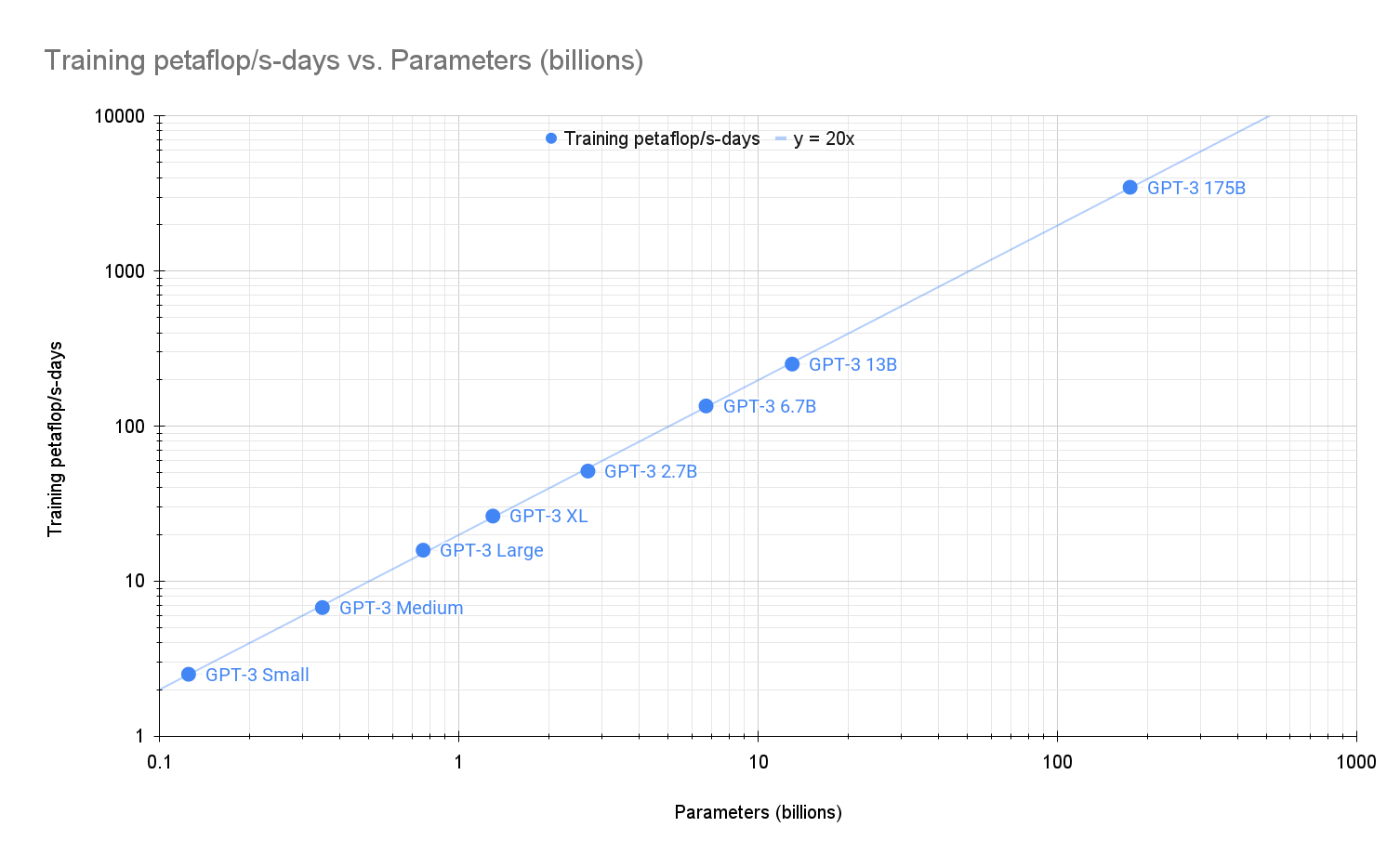
For GPT-3 models, every 1 billion parameter increase requires approximately 20 petaflop/s-days of compute. The commercial version of GPT-3, with 175 billion parameters, demands roughly 3,470 petaflop/s-days of compute power.
Benchmarking Against Frontier
The world’s fastest supercomputer, Frontier at Oak Ridge National Labs, cost $600 million to build and has a peak performance of 1.6 exaflop/s (1,600 petaflop/s). Training GPT-3 on Frontier would take over 2 days of continuous computation:
3,470 / 1,600 = 2.2 days
Frontier consumes 21 MW of power at peak usage, equating to about 1,090 MWh of energy over 2.2 days. Considering the average U.S. household uses 10,800 kWh annually, training GPT-3 uses the same amount of energy as approximately 100 homes use in one year.
Scaling Up to GPT-4
Although OpenAI has not disclosed details beyond GPT-3, estimates suggest GPT-4 has 1.76 trillion parameters. Assuming similar training efficiency:
- ~35,200 petaflop/s-days required
- ~22 days on Frontier
- Energy equivalent to over 1,000 households
This highlights how the immense scale of current and future LLMs introduces significant compute and power challenges. Companies are now focused on enhancing computational capabilities, exploring sustainable power options, and improving training efficiency to meet these demands.